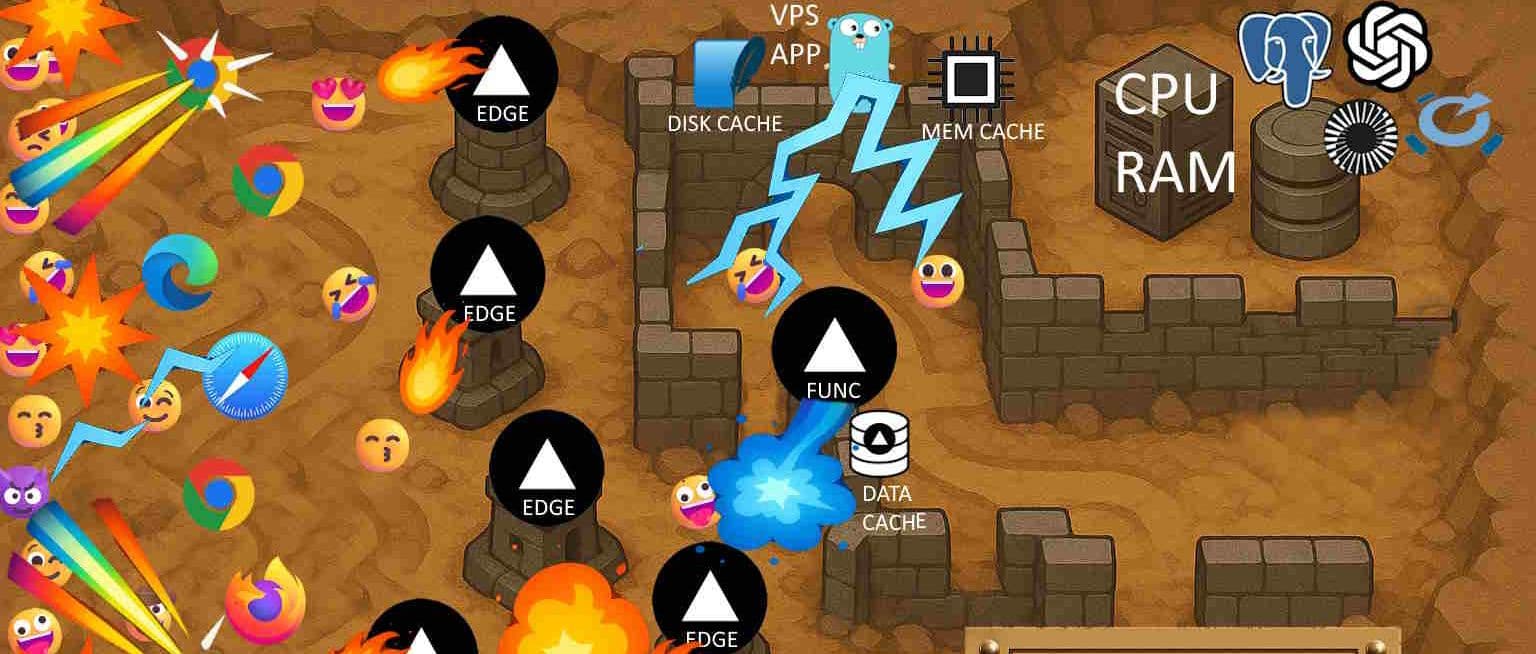
Saving Stuff To Use Again
For those of you who landed here directly and missed my implausible intro, this isn’t a game. It’s something even better: an article about caching!
I’ll describe the techniques used on my sites jasonthorsness.com and hn.unlurker.com. The latter is open-source so you can peruse the implementation.
If you are looking to defend a meager budget with web-exposed side projects from an onslaught of web traffic you might find these approaches helpful.
And if you are part of the problem, a user among countless others in your horde, driven en masse in wave after wave against my defenses — read on to scout my setup and find out whether or not it’s up to the challenge.
The article progresses through three difficulty levels:
| Difficulty Level | Description |
|---|---|
| Easy | Mostly-static sites |
| Medium | Data-driven dynamic sites |
| Hard | Authenticated per-user sites |
Easy: Mostly-Static Sites
Static means the content is the same for every user and doesn’t change as a function of time. For example, due to my sluggish pace of writing, jasonthorsness.com remains unchanged for weeks in between updates. Even then, my older articles like this one don’t change unless I adjust a common layout. For this kind of site, applying content-hashed resources, using a CDN, and keeping dynamic bits client-side is the dominant industry combination.
Content-Hashed Resources
To improve the handling of supporting resources (CSS, JS, images, etc.) a universal practice in
modern web frameworks is to add content hashes to the resource names. By deriving the name of the
file from its contents, you can consider a file with a given name unchanging. For example, on this
site, one of the fonts is at the time of writing served as
/_next/static/media/bd734242e06bd6ad-s.p.woff2 with the cache-control header of
public,max-age=31536000,immutable. The bd734242e06bd6ad part of the name is a hash of the file
contents. The CDN and the user’s browser will cache this file for as long as they want without
worrying about it becoming stale. If I ever change the font, the file will have a different name so
all caches will miss and fetch the new font from the origin.
If you open the network tab in your browser’s dev tools and refresh this page, you’ll see most resources are served in this manner and arrive in 0-1 ms from the memory or disk cache. This is simultaneously the least costly and lowest-latency sort of caching — nothing does any work except the user’s browser.

🏰 In Tower Defense lingo: content-hashed static files in the browser cache let you defeat waves of requests right at the spawn point.
CDNs
Resources referenced from outside the site itself, like the path you see in the URL bar, can’t have
hashes appended because the links would be broken whenever the content changes. The server instead
delivers the response with an “Etag” header that identifies the current version of the content. When
the browser requests the resource again, it includes the last Etag value in an “If-None-Match”
header. Whenever the current ETag on the server matches the If-None-Match value from the browser,
the server is allowed to respond with 304 Not Modified rather than the actual content.
If you open the network tab in your browser’s dev tools once more and refresh this page, you’ll see
/26 is served with a 304 response. You should also see fewer than 2 kiB transferred for the
entire page! If you see more than that, it’s likely browser extensions you have injecting stuff. Try
it again in Incognito Mode or with a guest profile.
A problem with 304 Not Modified is that there’s still a round-trip to the server. But is it really
a problem? If you look carefully at that network tab, you might see /26 served to you in fewer
than ~60 milliseconds. The single origin server for this page is somewhere in the eastern US, but
the reported latency will stay low worldwide. This is because rather than serving from the origin,
the resources are cached and served from a network of delivery points around the globe, commonly
described as a CDN (content-delivery network). This reduces load on the origin and ensures snappy
performance for users all over the world. Low-latency world-wide is important if you respect your
users — even this irrelevant blog regularly gets traffic from USA, Europe, and Asia.
This site uses Vercel’s CDN, which has at the time of this writing 119 locations to serve content. Beyond static resources, you can also run code in these locations to implement custom low-latency functionality.

🏰 CDN locations are the towers in-between the spawn point and your base. When things are working correctly they take care of most of the waves.
What About The Dynamic Parts?
Even a mostly-static site might have dynamic components. For example, beyond the city search edge function mentioned above, I have a VPS monitoring chart, some DIY analytics, some LLM silliness, and a page that requires users to sign in to compile code changes. All of these require additional dynamic content that varies by time or user input.
To ensure most content can remain optimized for static delivery, the dynamic parts are all handled via client-side JavaScript that makes separate API calls to dedicated dynamic API endpoints. This enables a clean separation of the static and dynamic parts of the site, and also helps prevent unnecessary triggering of dynamic functionality from crawlers and other bots.
🏰 Requests for dynamic resources typically must reach the origin. Fortunately in the Tower Defense metaphor the origin itself is not the end-goal of the creeps. They are after precious resources inside: CPU cycles and upstream APIs. Continue to the next difficulty level for some “inside the server” strategies for protection.
Medium: A Data-Driven Dynamic Site
A data-driven site has most of its content change automatically over time. This blog is not such a site, so for this section we’ll look at my recent project hn.unlurker.com. Unlurker falls fully into the dynamic category: it always shows only the latest activity from Hacker News. The content becomes stale quickly so caching is a challenge. The Unlurker site uses two layers of caching:
- short-term cache-control headers
- backend memory cache, single-instancing, and disk cache
Short-Term Cache-Control Headers
Even if you have a data-driven dynamic site, often the content can be treated as static for a short time. For Unlurker, new comments and stories only appear a few times a minute, so I can apply the following cache-control header:
public, max-age=15, s-maxage=15, stale-while-revalidate=15
- For the first 15 seconds, the content is considered fresh.
- For the next 15 seconds, the content is stale but will still be used. The CDN will fetch a fresh copy in the background.
- After 30 seconds, the content is fully stale and will not be used.
If you look at the headers from hn.unlurker.com you’ll only see
public, max-age=15 because the CDN strips the rest and handles them internally. To see the effect,
toggle options in the drop-downs back and forth every few seconds. You will see the latency stay at
< ~60 ms forever. The CDN does the expensive refresh from the origin in the background
asynchronously due to the stale-while-revalidate=15. You can inspect the X-Vercel-Cache header
to see whether the content was HIT (fresh) STALE (still used but triggered an asynchronous
refresh) or MISS (fully stale and fetched synchronously from the origin). For me this corresponds
to a latency of 1-2ms for local cache, ~60 ms for hit or stale from the CDN, and likely ~800 ms for
a miss as it goes all the way to my poor VPS and likely the HN API.

stale-while-revalidate is a relatively recent cache-control option. It keeps latency low for all
users; nobody “pays the price” for being the first to request after the cache expires. Control over
this header is why I couldn’t use NextJS for Unlurker — NextJS doesn’t seem to support it for
dynamic pages, and NextJS ISR has a major limitation compared to stale-while-revalidate in that it
doesn’t support a maximum staleness. For low-traffic sites, users can see hours-old content, which
is unacceptable. I switched to react-router on Vercel which doesn’t mess
with the headers.
With the options available on hn.unlurker.com, there are only 10 * 12 * 8 * 2 or 1920 possible combinations, refreshed at most once every 15 seconds, so this technique caps the front-end request rate to 128 requests per second, regardless of the incoming request rate from user’s browsers.
The front-end function in this case applies no further caching and each request initiates a single fetch to the backend API for data.
🏰 Is the Tower Defense metaphor breaking down yet? Short-term cache control headers are like the browser-cache and CDN towers we’ve discussed so far, clearing nearly all the creeps, but they periodically spawn a creep of their own that heads for the origin. Could this be a novel gameplay mechanic? You read it here first.
Backend Caches
The Unlurker backend runs on a shared 2 vCPU VPS. The program running there is the last chance to protect the CPU cycles and the upstream HN APIs. For dynamic sites like this one, caching and efficient request handling within the web server is just as important as leveraging browser caching and CDNs.
The Unlurker backend uses memory caching to protect the CPU cycles, then single instancing and disk caching to improve performance and protect the HN API.
Memory Caching
Anything expensive to compute that might be requested multiple times is useful to keep in a memory cache. Unlurker maintains a cache of normalized comment text for each item. The comments and stories themselves are stored in a memory cache as well for 60 seconds. This makes the cost of a request with no cache misses just a few hash lookups plus the response serialization.
Single-Instancing
Upon a memory-cache miss, the backend needs to fetch the story or comment from the disk cache or maybe even the HN API. These are relatively expensive operations. To reduce the cost, requests for the same resource are combined into a single request. This is easy in Go, typically using the singleflight package but in this case (for good integration with the memory cache) using a custom implementation. No matter how many requests come in for the same item concurrently, only one check will be made against the disk cache and only one request made to the HN API. Unlurker’s overall load on the HN API is likely lost in the noise (especially if I’ve created load by convincing enough people to try downloading the whole thing)
Disk Caching
Memory caching alone has a couple of issues: space in RAM is limited and process restarts clear the entire cache. To address these, Unlurker also keeps stories and comments in a disk cache in the form of a SQLite database. This is a bit slower than memory, but it effectively has no size limit and survives process restarts.
Rather than expire items after a fixed 60 seconds, the disk cache uses a “staleness” function based on the age of the story or comment. It slowly climbs from ~60 seconds for new items to ~30 minutes for items a few days old, then more rapidly increases until items more than a couple weeks old are considered immutable.
Requests for items are made in batches, so deriving the expiration from the creation time of items also helps eliminate clusters of expirations and spreads the requests made to the HN API out over time.
🏰 The memory cache, single-instancing, and disk caches are clusters of powerful towers right around the base taking care of almost all of the remaining creeps. If they are well-chosen, they can handle an incredible load, and the eventual number that pass to consume significant CPU and initiate requests to the HN API will be less than your health points. You’ve won!
Why Not Redis?
I have a single VPS, so I can get by with a simple SQLite database. If I had many instances of my API on separate servers, I might at some point want to replace the disk cache with a Redis instance and might consider using Redis for cross-server single-instancing. But for my site (and probably most other sites) it’s way beyond what the situation requires.
Hard: Authenticated Per-User Sites
Unfortunately for this article, I’ve only recently begun to add some authenticated features to my side projects. The article LLM not LLVM requires users to authenticate before they can use an LLM to “recompile” the examples on the page, but it’s solely a client-side function.
For per-user sites, the first step is always to identify and isolate the non-per-user pieces and serve them with the same techniques as for static and dynamic sites.
Beyond that, for the truly per-user pieces, caching at the edge becomes much more challenging — data is often too sensitive to cache in the CDN, and even if you could, it’s per-user anyway so cache hits are rare. The caching solution becomes a partnership between the user’s browser and the origin server, which understands the authentication scheme and can cache per-user responses using the same memory and disk and single-instancing schemes already mentioned.
Strategies that download data to the user’s browser and handle requests locally can help. This way many functions over slowly-changing data can be computed on the client, and only deltas need to be synced from the server.
There are many more approaches — maybe my next project should require authentication so I can explore this difficulty level a bit more.
Conclusion
Caching has always been critically important for site performance, and as more-and-more sites depend on metered APIs (like OpenAI’s LLMs) and serverless hosting providers (like Vercel) it’s become just as important for cost management. Get the cache architecture right and you’ll be surprised at how far you can stretch a tiny budget with only a few vCPU and a few gigabytes of RAM. Keep in mind, the sites of the past ran on servers with a minuscule fraction of the resources given to sites today, and in many cases they probably handled the load far better thanks for more careful caching and planning.
Thanks for reading! If you have any questions or comments, please reach out to me on X. If anyone cares to develop Tower Defense: Cache Control, go right ahead!